COVID19 Lockdown Dev Log – Day 20, Regular Expressions And Failing
What I Worked On
Adding data correctly formatted to a ‘.CSV’ file.
What I Learned
Note: this is a follow-up on yesterday’s post 😀
I learned a lot about regular expressions (regex) and what it is. I know about it but haven’t worked much with it. I still struggle to apply it correctly to my scraped HTML data. So today has just been ‘trial and error’. I did manage to achieve my result to some extend with a foreach loop though:
// index.js
//...code
const lists = $('.list');
lists.each((index, element) => {
const articles = [];
const title = $(element).find('.list__title').text();
const list = $(element).find('.list-article__title');
list.each((i, item) => {
const listItem = $(item).text();
articles.push(`${listItem}\n`)
});
//Write a row to CSV (headers)
writeStream.write(`${title} \n ${articles} \n`);
//...codeI am looping through a list of elements in ‘lists’ which has an element with another list – the ‘list’ in the loop. We loop through that aswell and populate the ‘articles’ array with each item. The ‘\n’ is for making the data display “correctly” in a ‘.CSV’ – in this case it’s the ‘articles.csv’ as I talked about yesterday.
The result of the ‘CSV’ file looks like this when you open it in MS Excel:
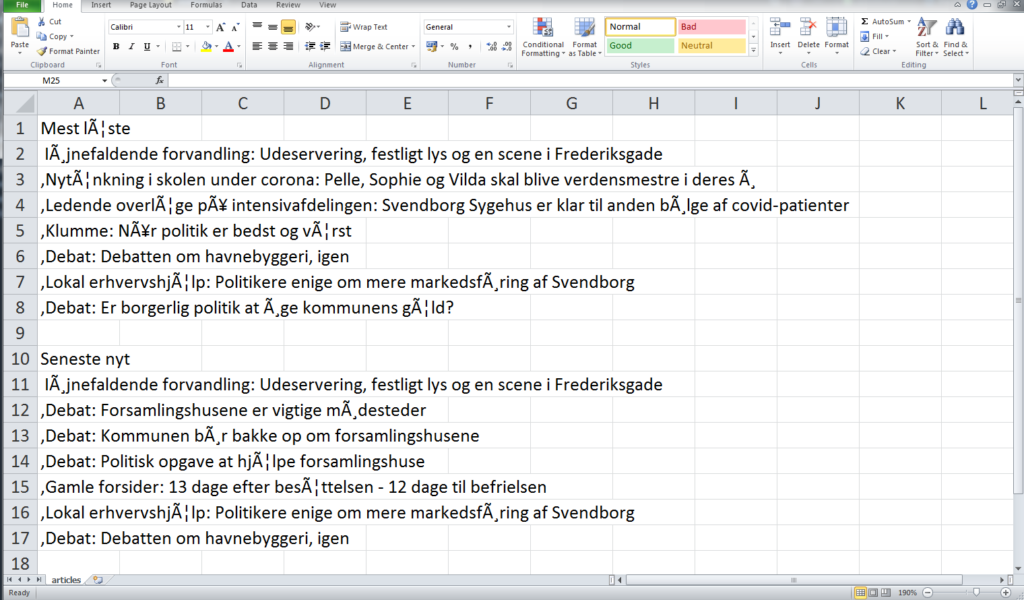
The Danish letters “æ, ø, å” are messing with the text here, but to some extend, I guess this is okay? 😀 I would just rather do the sorting of article headlines into their own line with a regex rather than a loop mixed with some linebreaks. It feels cleaner. Furthermore I need to get rid of the commas at the start of each article headline.
If I don’t use linebreaks, the article headline data looks like this:
/*
Iøjnefaldende forvandling: Udeservering, festligt lys og en scene i FrederiksgadeLedende overlæge på intensivafdelingen: Svendborg Sygehus er klar til anden bølge af covid-patienterKlumme: Når politik er bedst og værstNytænkning i skolen under corona: Pelle, Sophie og Vilda skal blive verdensmestre i deres øDebat: Debatten om havnebyggeri, igenLokal erhvervshjælp: Politikere enige om mere markedsføring af SvendborgDebat: Er borgerlig politik at øge kommunens gæld?
*/It all comes in one line. Each new article headline begins right after the one before it ends, meaning that you have a lowercase letter followed by a capital letter with no spaces between. This is where I would have to split the article to a new line.
I thought the regex for this would be rather complicated, but it can be done in and expression like so:
const regex = /[a-z][A-Z]/gmThis regex looks through the entire string and finds where a lowercased letter is followed by a capitalized letter with no space between them – at least according to the online regex tool I tested it in:
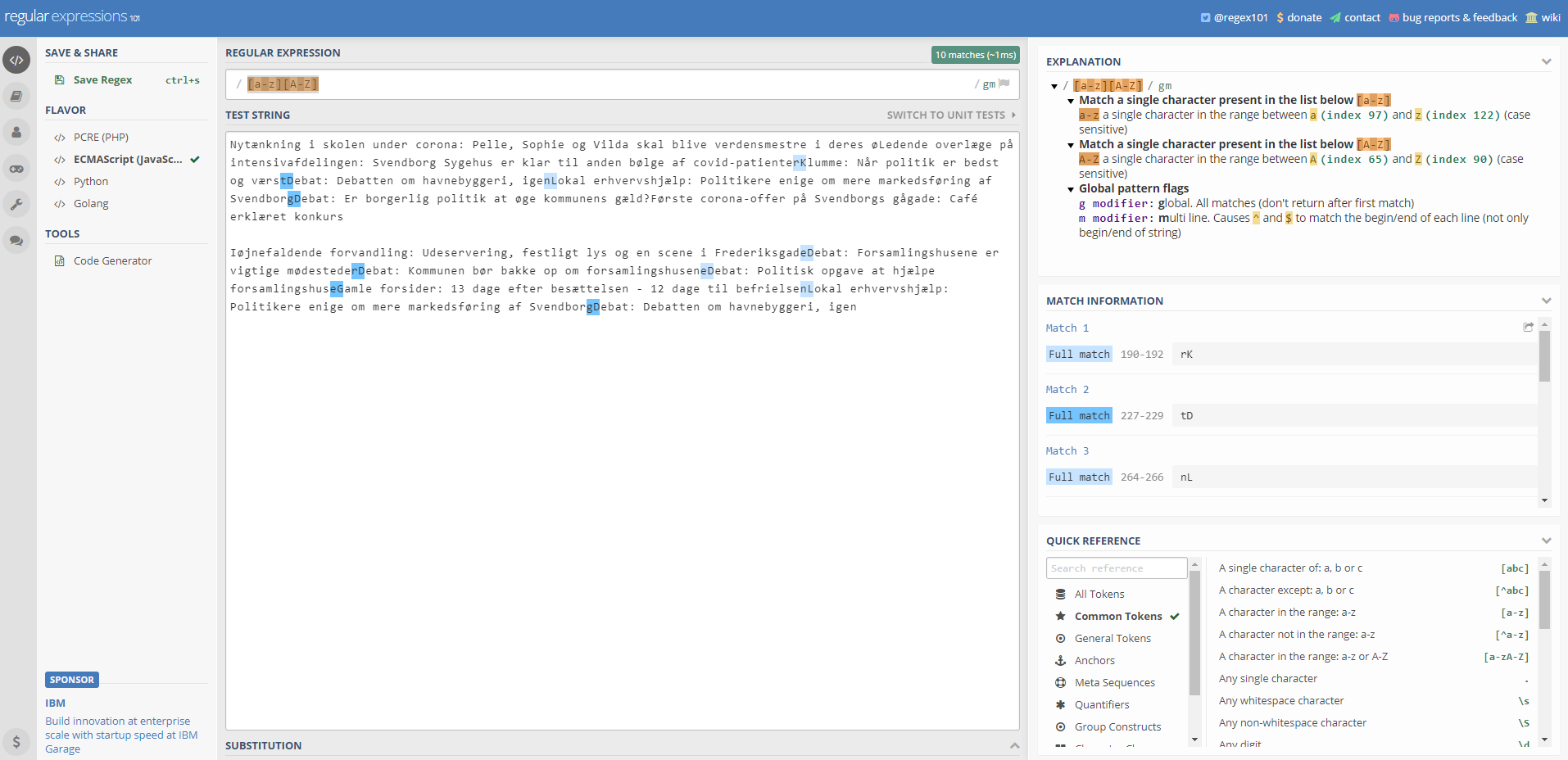
I’m almost there! I will post the solution in tomorrow’s blogpost (given that I solve it of course 😀 ).
What Distracted Me During The Day
- Basically anything that is not regex related 😀
Resources
- Regular expressions tutorial/intro – https://www.youtube.com/playlist?list=PL4cUxeGkcC9g6m_6Sld9Q4jzqdqHd2HiD
- Regex online tool – https://regex101.com/
- Regex cheatsheet page (love the name 😀 ) – https://ihateregex.io/