COVID19 Lockdown Dev Log – Day 18, Webscraping with Cheerio
What I Worked On
Webscraping a newspage for articles about news/stories in my local area.
What I Learned
There are multible frameworks/tools for webscraping. I won’t focus on that though, but I will let you know that I had a look at Puppeteer and Cheerio. In short, Puppeteer seems to be the one to use for more complex webscraping and Cheerio is for simple webscraping. I went with Cheerio, which is used with NodeJs (check Resources for link to their website). The syntax is similar to jQuery. I haven’t used jQuery for years, but it’s a syntax I remember as easy to use. 😀
Let’s get coding! I created a new folder with npm and installed Cheerio and Request. Request is a lightweight HTTP module, which will be used to request the URL:
npm install cheerio requestThat’s it! Now let’s add some code to the ‘index.js’ file (created from npm init):
// index.js
const request = require('request');
const cheerio = require('cheerio');
request('https://faa.dk/svendborg', (error, response, html) => {
if(!error && response.statusCode == 200) {
//...scraper code
})
}
})
Firstly we import request and cheerio into our file. After that we use ‘request’, which takes two arguments: the URL as a string, and a function.
The function needs 3 arguments ‘(error, response, html)’. The ‘error’ is rather selfexplanatory, while ‘response’ is the HTTP response we will get and ‘html’ is the HTML of the webpage we request with the URL. The ‘if’ statement makes sure that our code is ran if we have no errors and the HTTP response is ‘200’ .
Let’s first look at the HTML we want to get:
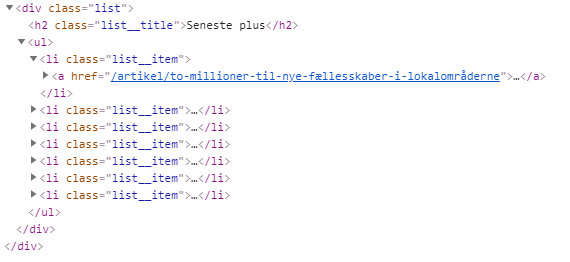
The HTML contains some CSS classes. The goal is to target these classes, which are the ‘list__title’ and all the ‘list__item’ in the ‘list’ <div>. With that, we will get a list with “most recent” and “most read” articles. It also has a “Most Recent Plus”, which is for subscribers, but I don’t want that since I am not a subscriber. This will be filtered out in the code. Let’s write the code to scrape the HTML needed:
// index.js
const request = require('request');
const cheerio = require('cheerio');
request('https://faa.dk/svendborg', (error, response, html) => {
if(!error && response.statusCode == 200) {
//load html and create a 'jQuery'-like selection variable.
const $ = cheerio.load(html);
const lists = $('.list');
lists.each((index, element) => {
const title = $(element).find('.list__title');
const list = $(element).find('ul');
if(title.text() === "Seneste plus") {
return
}
console.log(title.text().replace(/\s\s+/g, ''));
console.log("---------------------------------");
console.log(list.text().replace(/\s\s+/g, ''));
})
}
})
We wrap the ‘cheerio.load(html)’ into a ‘$’ to get the “jQuery Experience”. 😀 After targeting the ‘list’ <div> we loop through it to get the HTML elements and grab the data we want. In this case, it’s the title of the list and the list of headlines. The console log reveals that we get the data we want:

“Seneste nyt” are the most recent articles and “Mest læste” are the most read articles. The next step is to sort it out so the articles are not all in one line and also add it to a ‘.CSV’ file.
This is all for now. I am continuing this project tomorrow 😀
Side note: Request is deprecated as of February 2020. I noticed this a bit late, so I will rewrite the HTTP requests in Axios later.
What Distracted Me During The Day
- Snapchat
- Nordnet
- Cleaning up the desktop (you know, when you “just want to delete that one folder” and you end up cleaning the entire desktop screen for files you no longer use) 😀
Resources
- Puppeteer vs Cheerio – https://www.reddit.com/r/node/comments/8p6um8/when_should_you_use_puppeteer_vs_cheerio_for_web/
- Cheerio docs – https://www.reddit.com/r/node/comments/8p6um8/when_should_you_use_puppeteer_vs_cheerio_for_web/
- Traversy Media showcasing Cheerio – https://www.youtube.com/watch?v=LoziivfAAjE